Sagen Sie uns, wie wir helfen können
Vertrieb & Preise
Speak to a rep about your business needs
Hilfe & Support
See our product support options
Allgemeine Anfragen und Standorte
Kontakt
Was ist Datenextraktion? Definition, Werkzeuge & Methoden
Die Datenextraktion ist grundlegend für das Datenmanagement, um Daten für eine nachfolgende Analyse und fundierte Entscheidungsfindung zu konsolidieren.
BMC-Tools mit Datenextraktionsfunktionen

Control-M
Umfassende Datenpipeline-Orchestrierung ist nur eine leistungsstarke Fähigkeit, die Ihr Unternehmen reibungslos am Laufen hält und Ihnen bei jedem Schritt Vertrauen gibt.
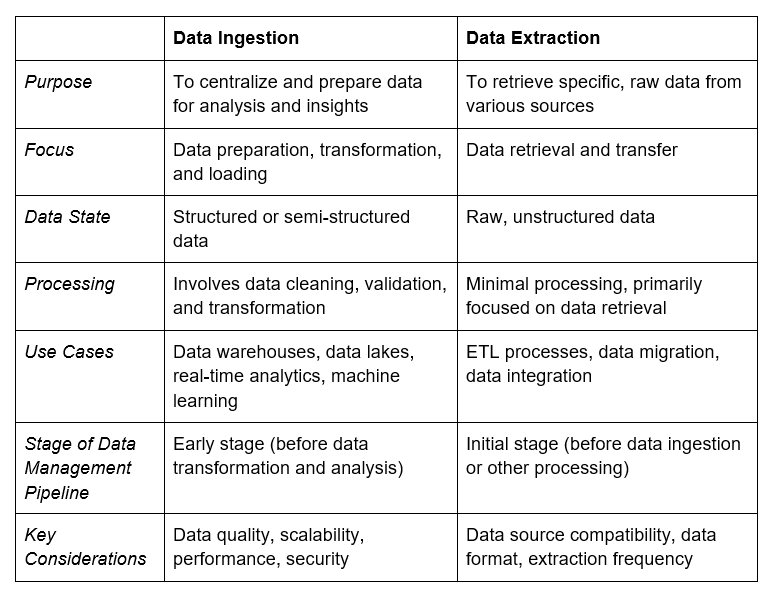
Erfahren Sie mehrWas ist der Unterschied zwischen Datenaufnahme und Datenextraktion?
Die Datenextraktion beinhaltet das Abrufen spezifischer, roher Daten aus unterschiedlichen Quellen (z. B. Tabellenkalkulationen, Sensoren, Transaktionssystemen) vor der Verarbeitung und Nutzung.
Datenaufnahme zentralisiert und bereitet Datensätze für verschiedene Anwendungen vor, mit dem Ziel, umsetzbare Erkenntnisse zu schaffen (z. B. Berichte, Echtzeit-Datenkonsolidierung).
Arten von Big-Data-Extraktionstools
ETL-Werkzeuge
Automatisierte Lösungen, die die Extraktion, Transformation und das Laden von Daten optimieren und so die Effizienz und Datenqualität verbessern.
Batch-Verarbeitungswerkzeuge
Effiziente Werkzeuge, die große Datenmengen in geplanten Chargen extrahieren, die Ressourcennutzung optimieren und die Systembelastung minimieren.
Open-Source-Tools
Anpassbare und kosteneffiziente Werkzeuge, die technische Expertise zur Implementierung und Wartung erfordern und Flexibilität sowie Community-Unterstützung bieten.
Ablauf
Wie läuft der Datenextraktionsprozess ab?
Schritt 1: Daten regelmäßig validieren und Daten bereinigen
Schritt 2: Identifizieren und lokalisieren Sie die zu extrahierenden Daten
Schritt 3: Datenänderungen identifizieren
Schritt 4: Bestimmen, wo die Daten gespeichert werden
Schritt 5: Starten Sie den Datenextraktionsprozess
Schritt 6: Setzen Sie einen umfassenden Datenmanagementplan fort
Schritt 7: Dokumentieren, testen und regelmäßig prüfen
Schritt 1: Daten regelmäßig validieren und Daten bereinigen
Schritt 2: Identifizieren und lokalisieren Sie die zu extrahierenden Daten
Schritt 3: Datenänderungen identifizieren
Schritt 4: Bestimmen, wo die Daten gespeichert werden
Schritt 5: Starten Sie den Datenextraktionsprozess
Schritt 6: Setzen Sie einen umfassenden Datenmanagementplan fort
Schritt 7: Dokumentieren, testen und regelmäßig prüfen
Ressourcen
Themen im Zusammenhang mit Datenextraktion
Datenextraktion und ETL
Entdecken Sie, wie die Datenextraktion, der erste Schritt im ETL-Prozess, die Kraft Ihrer Daten freisetzt und die Grundlage für fundierte Entscheidungen bereitet.
Erfahren Sie mehrEine große Einführung in Big Data
Verstehen Sie die 3V-Bereiche von Big Data, ihre Kernkonzepte und die neuesten Big-Data-Trends im Geschäftsbereich, damit Sie auf dem Laufenden bleiben.
Erfahren Sie mehrBig Data: Eine große Einführung
Verstehen Sie die 3V-Bereiche von Big Data, ihre Kernkonzepte und die neuesten Big-Data-Trends im Geschäftsbereich, damit Sie auf dem Laufenden bleiben.
Erfahren Sie mehr